

If you’ve ever wondered how search engines decide what parts of your website to show in search results, you’re not alone. One small but powerful file plays a big role in that decision—the robots.txt file.
Let’s break it down in simple terms so it’s easy to understand, whether you’re a business owner, blogger, or just getting started with SEO.
What Is a Robots.txt File?
A robots.txt file is a simple text file that lives in the root directory of your website (like abc.com/robots.txt). It tells search engine bots—like Googlebot or Bingbot—what they can and cannot access on your site.
Think of it like a traffic controller. It guides bots and crawlers, helping them know which parts of your site are open to explore and which ones should stay off-limits.
Is Robots.txt Necessary? Not mandatory, but highly recommended.
While a robots.txt file isn’t mandatory for a website to function, it’s highly recommended, especially if you want to improve your SEO strategy and site structure. This file helps guide search engine bots on which pages or sections of your website should or shouldn’t be crawled.
For instance, if you have duplicate content, staging pages, or private sections like admin panels, using a robots.txt file helps prevent them from being indexed in search results. It’s also useful for managing your crawl budget, which is particularly important for larger websites where search engines may not crawl every page. By directing bots away from unimportant or non-SEO-friendly pages, you can ensure they focus on the content that truly matters for rankings. Overall, having a properly configured robots.txt file contributes to a cleaner, more organized, and more search engine-friendly website.
Then yes, a robots.txt file is important for SEO and structure.
Why Is It Important?
Search engine bots crawl websites to understand what your content is about so they can index and rank your pages. But not every page on your website needs to be crawled. Here’s why that matters:
1. Controls What Gets Crawled
Sometimes, you don’t want bots wasting time on things like:
- Admin or login pages
- Cart and checkout pages
- Duplicate content
- Private files or scripts
With a robots.txt file, you can block them from crawling these parts.
2. Saves Crawl Budget
Google gives your site a limited “crawl budget”—the number of pages it crawls in a given time. If bots spend time crawling unimportant pages, they might skip the ones that actually matter (like your blog posts or product pages). The robots.txt file helps direct bots to focus on high-priority content.
3. Protects Sensitive Information
Although it’s not foolproof security, using robots.txt can help hide files or folders you don’t want to appear in search results. For example, if you’re testing a new site feature, you can block that folder until you’re ready to launch.
4. Improves SEO and User Experience
A well-structured robots.txt file can boost your SEO indirectly. How? By helping bots crawl your most valuable content first and avoiding confusion with duplicate or low-quality pages, you give your website a cleaner, more focused presence in search engines.
How Many Robots.txt Files Are There?
Technically, there is only one robots.txt file per website, and it must be located in the root directory of the site.
Example:
For a website like www.abc.com, the robots.txt file should be accessible at:
https://www.abc.com/robots.txt
Key Points:
- You can’t have multiple robots.txt files for different sections of your site.
- Only one file is recognized by search engines, and it must be in the root of your domain or subdomain.
- If you have multiple subdomains (e.g., blog.abc.com, shop.abc.com), each subdomain can have its own separate robots.txt file.
So, while only one robots.txt file per domain or subdomain is allowed, you can have different robots.txt files for different subdomains if needed.
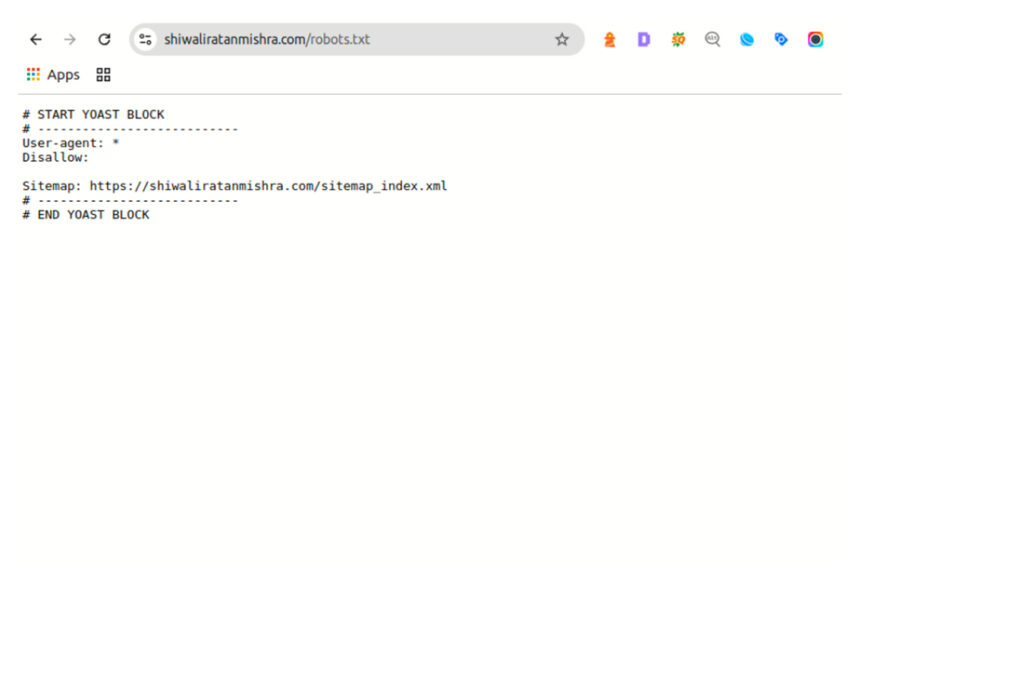
What Does It Look Like?
Here’s a super basic example of a robots.txt file:

A Few Things to Keep in Mind
- A robots.txt file is public. Anyone can type yoursite.com/robots.txt and see it.
- It doesn’t prevent access to files—it just tells bots not to crawl or index them.
- If you really need to keep something private, use password protection or other security measures.
Can Robots.txt Reproduce
A robots.txt file itself cannot “reproduce” in the sense of creating multiple copies or versions automatically. However, you can create different robots.txt files for various subdomains of your website if needed, as each subdomain can have its own distinct file. Additionally, if you’re managing a large website, you might generate multiple versions of robots.txt for testing or staging purposes, but only one version is used at a time by search engines. It’s essential to ensure the robots.txt file is properly configured for each domain or subdomain to control which pages search engines can crawl and index.
How to Create a Robots.txt File: Step-by-Step Guide
Open a Text Editor
Start by opening a simple text editor like Notepad (Windows) or TextEdit (Mac)
Create the Basic Structure
In the text editor, type the basic structure for the robots.txt file. Here’s an example:
User-agent: *
Disallow: /private/
Allow: /public/
User-agent: specifies which search engine bot the rule applies to (e.g., * for all bots, or you can specify individual ones like Googlebot).
Disallow: tells bots which pages or sections they should not crawl.
Allow: explicitly allows bots to crawl certain sections, even if other rules block access.
Add Specific Directives
Depending on your needs, add specific directives for different pages or sections. For example:
User-agent: Googlebot
Disallow: /private/
Allow: /public/
- This example tells Googlebot not to crawl anything in the /private/ directory but allows access to the /public/ directory.
- Save the File
After adding your rules, save the file as robots.txt. Make sure the file is saved in plain text format. - Upload to the Root Directory
Upload the robots.txt file to the root directory of your website using FTP or your website’s file manager. The file should be accessible at https://www.abc.com/robots.txt. - Test Your Robots.txt File
After uploading, use tools like Google Search Console’s “Robots.txt Tester” to verify that the file is properly configured and doesn’t block essential pages unintentionally.
By following these steps, you can effectively manage which pages search engines can crawl and index on your website!
Final Thoughts
The robots.txt file might be tiny, but it has a big job. It helps you:
- Keep search engines focused on your best content
- Save crawl budget
- Avoid unnecessary indexing
- Maintain a clean SEO strategy
Whether you run a blog, an online store, or a corporate website, having a properly set up robots.txt file is a simple step that makes a noticeable difference.
Want to check your own robots.txt file? Just add /robots.txt to your domain name in the browser and see what it says. And if it’s missing or messy, now’s a great time to fix it!

April 26, 2025
SEO for Shopify and WooCommerce: How to Increase...

April 26, 2025



