
What Is a Data Pipeline? How It Works and Why It Matters (Beginner-Friendly Guide)
1. Introduction: Why Do Businesses Need Data Pipelines?
Every business today generates massive amounts of data, from websites, apps, payments, sensors, CRM systems, marketing platforms, and more. However, raw data alone has no value until it is collected, cleaned, organized, and delivered in a format that people or machines can understand.
This is where a data pipeline becomes essential.
A data pipeline automatically moves data from its source to a destination like a database, data warehouse, or analytics platform, while also cleaning, transforming, and preparing it along the way. Instead of manually exporting and arranging data (which is slow and error-prone), a data pipeline ensures:
- Data is always accurate
- Data is updated in real time or on schedule
- Data teams spend less time fixing and more time analyzing
- Decisions are based on clean, reliable insights
With data pipelines, businesses can create real-time dashboards, train ML models, personalize customer experiences, detect fraud instantly, forecast demand, and make faster decisions. In short, pipelines turn raw data into actionable intelligence, helping companies grow, innovate, and stay competitive.
Table of Contents
2. How Data Pipelines Work: Step-by-Step Lifecycle
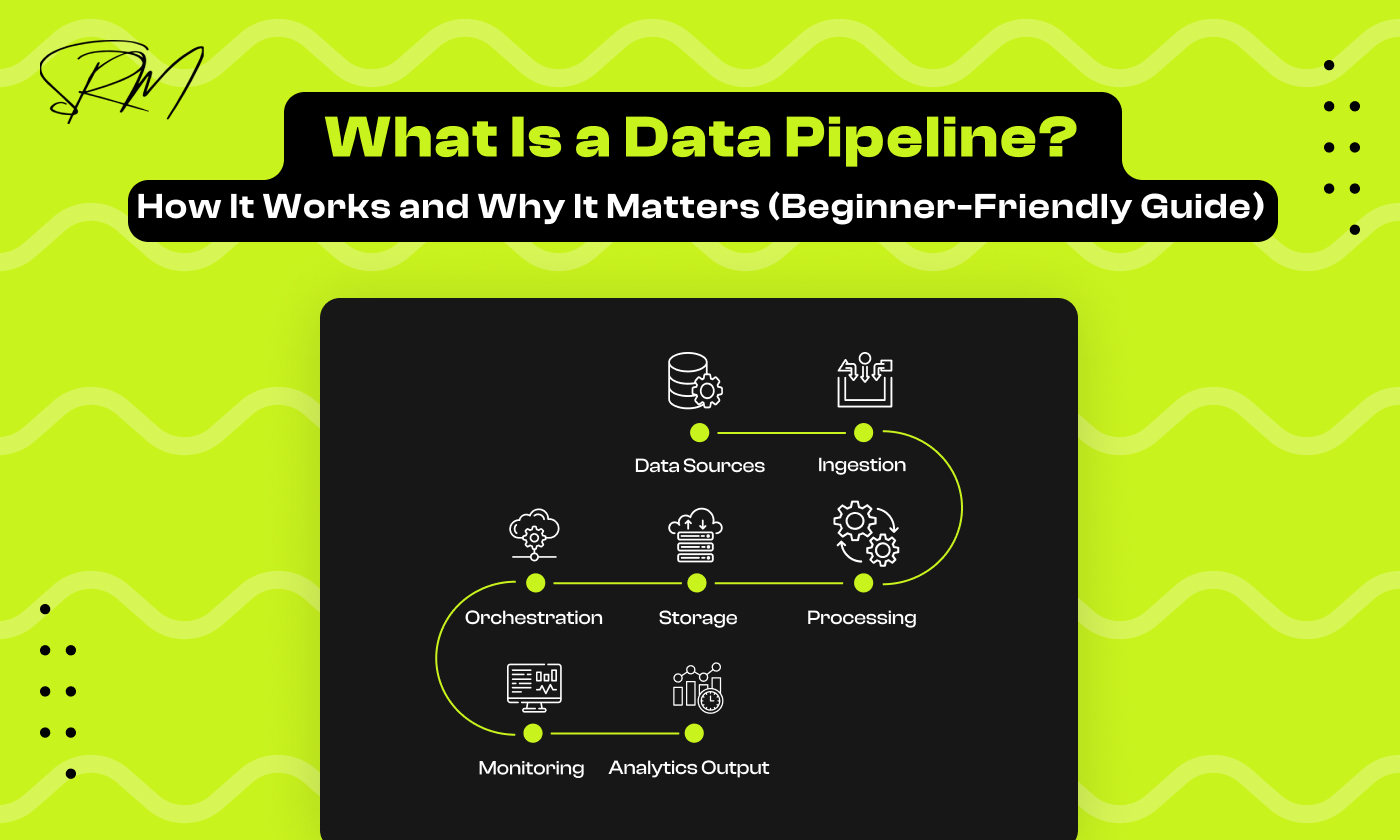
A data pipeline is a system that collects data from different sources, processes it into a usable format, stores it securely, and delivers it to tools or applications that need it. To understand how it works, think of it as a continuous flow of data from raw state to actionable insights. A complete pipeline lifecycle normally includes six core stages.
What Is a Data Pipeline?
A data pipeline is a system that automatically moves data from one place to another, while also cleaning, transforming, and preparing it for analysis or machine learning.
Think of it like a water pipeline:
- The source is where the water (data) comes from,
- The pipes move and clean it,
- The destination safely stores it for use.
2.1 Data Ingestion
Data ingestion is the first and most essential stage. It refers to collecting or importing data from different sources such as websites, mobile apps, sensors, CRM systems, databases, cloud platforms, social media, and third-party applications.
Ingestion can happen in two ways:
- Batch ingestion, where data is collected at intervals (hourly, daily).
- Real-time ingestion, where data flows continuously with no delay.
This step ensures that every required data point is captured accurately and delivered to the pipeline for processing.
2.2 Data Processing and Transformation
Once data is ingested, it is often raw, unclean, and inconsistent. Data processing transforms this messy data into structured, understandable information. This stage may include:
- Cleaning missing or duplicate records
- Standardizing formats (dates, currencies, units)
- Aggregating and combining datasets
- Enriching data using external sources
- Applying business rules or calculations
Transformation prepares data so it becomes trustworthy and ready for analytics, reporting, or automation.
2.3 Data Storage
After processing, data must be stored in a secure and scalable location. The choice of storage depends on the use case, such as analytics, machine learning, real-time decision making, or application development.
Storage systems also define how fast data can be queried, how easily it can be shared, and how much it will cost to maintain over time. Modern pipelines therefore choose storage based not only on size and speed but also on governance requirements like compliance, data quality rules, and access control.
This layer ensures the business has a reliable and structured repository where data can be accessed efficiently by teams and applications.
- Data Warehouse for analytics (example: BigQuery, Snowflake).
- Data Lake for unstructured or large-scale raw data (example: AWS S3).
- Data Mart for department-specific reporting.
- Database for transactional applications.
This layer ensures data remains accessible, secure, and optimized for query performance.
2.4 Orchestration and Scheduling
Orchestration manages when and how each pipeline process runs. It automates pipeline tasks, handles dependencies, monitors performance, and retries failed operations to avoid data loss or delay. This ensures the pipeline runs consistently even when large data volumes or complex workflows are involved.
Tools like Apache Airflow, Prefect, and Dagster ensure that each step in the pipeline executes in the correct order without manual intervention. These tools can trigger tasks based on time schedules (hourly, daily, weekly) or event triggers such as a new file arrival, an API update, or a system change.
Orchestration also includes logging, alerts, and workflow optimization. It helps engineers track failures, rerun jobs automatically, and adjust task priorities. This layer is crucial for maintaining reliability, reducing manual effort, and ensuring smooth and predictable data flow across the entire pipeline.
2.5 Data Consumption
Once data is stored and ready, various users and systems consume it for different purposes such as analytics, reporting, machine learning, business operations, and automated decision-making. It is the stage where processed data turns into business value.
Users may access the data through dashboards, APIs, reports, or directly query databases for custom analysis. In many organizations, this layer also powers real-time systems like recommendation engines, fraud detection models, customer personalization tools, or inventory automation.
Effective data consumption requires well-modeled, high-quality data so teams can trust the insights and confidently make data-driven decisions.
- Business Intelligence dashboards (Power BI, Tableau, Looker)
- Machine Learning models and predictions
- Business applications and real-time decision systems
- Automated alerts and reports
- Analytics platforms and customer-facing apps
At this final stage, data converts from stored assets into valuable insights, driving business decisions and automation.
3. Types of Data Pipelines
Data pipelines can vary depending on how data is collected, processed, and delivered. Choosing the right type depends on business requirements, data volume, speed, and the type of insights needed. The most common types of data pipelines are designed to handle different scenarios, from large-scale historical data analysis to real-time monitoring and decision-making.
Selecting the appropriate pipeline ensures that businesses can process data efficiently, reduce latency, maintain accuracy, and make informed decisions. It also helps optimize resources, manage costs, and scale the data infrastructure as the organization grows. Understanding the differences between pipeline types is essential for designing systems that meet both technical and business objectives.
3.1 Batch Data Pipeline
A batch pipeline collects and processes data in scheduled intervals, such as hourly, daily, or weekly. It is ideal for use cases where real-time updates are not critical. In this type of pipeline, data from multiple sources is accumulated over a period and then processed together as a single batch.
Batch pipelines are commonly used for generating summary reports, historical analytics, and large-scale data processing where speed is less important than accuracy. They are simpler to implement and maintain, and can efficiently handle large volumes of data without putting continuous load on the system.
Example: An e-commerce company may generate daily sales reports from the previous day’s transactions.
Advantages:
- Simple to implement and maintain
- Can handle large volumes of data at once
- Cost-effective for non-urgent analytics
Limitations:
- Data is not updated in real time
- Not suitable for scenarios requiring immediate action
3.2 Real-Time Data Pipeline
A real-time pipeline processes and delivers data as soon as it is generated. This allows businesses to act on fresh data immediately. Real-time pipelines continuously monitor incoming data streams and update analytics, dashboards, or applications without delay.
They are ideal for use cases where immediate insights are critical, such as fraud detection, live customer interactions, stock price monitoring, or operational alerts. While more complex and resource-intensive than batch pipelines, real-time pipelines provide a competitive advantage by enabling faster decision-making and instant responsiveness to changing conditions.
Example: A banking system detecting fraudulent transactions the moment they occur.
Advantages:
- Immediate insights and decision-making
- Improves customer experience through real-time updates
- Useful for alerting, monitoring, and automation
Limitations:
- More complex and costly than batch processing
- Requires robust infrastructure and monitoring
3.3 Streaming Data Pipeline
Streaming pipelines continuously ingest and process data in small chunks as it is generated. Unlike real-time pipelines, streaming pipelines are optimized for very high-volume, fast-moving data sources and can handle large-scale, continuous flows of information efficiently.
They are commonly used in scenarios such as IoT sensor monitoring, clickstream analysis, financial tick data, or telemetry from connected devices, where even slight delays in processing could impact business outcomes. Streaming pipelines allow organizations to analyze, filter, and act on data instantly, providing near real-time insights while managing massive amounts of rapidly changing information.
Example: IoT sensor data from manufacturing machines or telemetry from connected vehicles.
Advantages:
- Handles high-speed data efficiently
- Suitable for monitoring and predictive analytics
- Provides near-instant insights on large-scale data
Limitations:
- Requires specialized tools (Kafka, Flink, Spark Streaming)
- Complexity in error handling and scaling
3.4 Hybrid Pipeline
Hybrid pipelines combine batch and real-time processing to take advantage of both approaches. Organizations can process most data in batches while handling critical streams in real time, allowing them to balance speed, efficiency, and cost.
This approach is particularly useful for businesses that need periodic large-scale analysis alongside immediate alerts or updates, such as e-commerce platforms updating inventory in real time while generating daily sales reports. Hybrid pipelines provide flexibility, scalability, and reliability, enabling organizations to meet diverse data processing needs without compromising performance.
Example: Retail businesses may update inventory in real time while generating daily sales summary reports in batch mode.
Advantages:
- Flexible and scalable
- Balances cost and speed
- Supports multiple use cases within the same pipeline
Limitations:
- More complex to design and maintain
- Requires careful orchestration and monitoring
3.5 Data Lakehouse Pipeline
A data lakehouse pipeline integrates features of both data lakes and data warehouses. It can store raw, unstructured data while providing structured, analytics-ready layers on top. This allows organizations to combine large-scale data storage with fast, queryable analytics, eliminating the need to maintain separate systems.
Data lakehouse pipelines are ideal for businesses that require both advanced analytics and machine learning capabilities on the same dataset. They provide scalability, flexibility, and cost efficiency, making it easier to manage historical data, real-time streams, and predictive analytics within a unified platform.
Example: Organizations using Delta Lake or Apache Iceberg to combine historical data and real-time analytics.
Advantages:
- Unified storage for raw and processed data
- Supports both BI and advanced analytics
- Scalable for cloud-based infrastructure
Limitations:
- Requires specialized architecture and tools
- Initial setup can be complex
4. Data Pipeline Architecture
Data pipeline architecture defines how data flows from its source to the final destination and how it is processed along the way. The architecture chosen impacts scalability, reliability, processing speed, and ease of maintenance. Organizations select architectures based on business needs, data volume, latency requirements, and technology stack.
The right architecture ensures that data is processed efficiently, remains accurate and consistent, and can handle both current and future growth. It also helps in reducing bottlenecks, simplifying monitoring, and supporting multiple use cases, from analytics and reporting to machine learning and real-time decision-making.
Some common pipeline architectures include:
4.1 Basic Architecture
The basic pipeline architecture follows a simple flow:
Source → ETL/ELT → Storage → BI/ML
- Source: Data is collected from databases, APIs, applications, or devices.
- ETL/ELT: Data is Extracted, Transformed, and Loaded (ETL) or Extracted, Loaded, and Transformed (ELT).
- Storage: Data is stored in warehouses, lakes, or lakehouses.
- BI/ML: Data is used for dashboards, analytics, or machine learning models.
This architecture is straightforward, easy to implement, and works well for small to medium-scale pipelines where complex processing is not required.
4.2 Lambda Architecture
Lambda architecture is designed for systems that need to process both real-time and batch data. It has three layers:
Batch Layer: Stores historical data and processes large datasets in batches.
Speed Layer: Handles real-time data to provide low-latency insights.
Serving Layer: Combines results from batch and speed layers to deliver a complete view.
Lambda architecture is ideal for applications that require both accurate historical analysis and up-to-the-minute real-time insights, such as fraud detection or online recommendation engines.
4.3 Kappa Architecture
Kappa architecture simplifies the pipeline by using a single streaming layer to process both real-time and historical data. Unlike Lambda, it avoids the complexity of maintaining separate batch and speed layers.
Stream Layer: Handles all incoming data as a continuous stream.
Storage Layer: Stores processed results and historical data for reference.
Kappa architecture is preferred for high-volume, real-time systems where minimizing complexity and maintaining consistency is important, such as IoT monitoring or financial transactions.
4.4 Medallion Architecture
Medallion architecture is a layered approach commonly used in data lakehouses. It organizes data into multiple stages:
Bronze Layer: Raw, unprocessed data ingested from sources.
Silver Layer: Cleaned and transformed data ready for analytics.
Gold Layer: Aggregated, business-ready data for dashboards, ML, and reporting.
This architecture ensures data quality, traceability, and efficiency, making it easier to manage large-scale pipelines in modern cloud environments.
4.5 Microservices-Based Pipeline Architecture
In a microservices-based pipeline architecture, the data pipeline is divided into independent, loosely coupled services, with each service responsible for a specific task such as data ingestion, transformation, storage, or delivery. This modular approach provides several advantages, including improved scalability, easier maintenance, and greater flexibility. Each microservice can be updated, scaled, or deployed independently without impacting the rest of the pipeline, allowing teams to make changes or add new features quickly and safely.
This architecture promotes fault isolation, meaning that if one service fails, it does not bring down the entire pipeline. It also enables teams to adopt different technologies or programming languages for different services based on requirements, improving efficiency and innovation. This makes microservices-based pipelines ideal for organizations handling complex, high-volume data workflows and seeking agility, reliability, and long-term scalability in their data infrastructure.
5. Core Components of a Data Pipeline
A data pipeline is made up of several critical components that work together to ensure data is collected, processed, stored, and delivered reliably. Each component plays a specific role in the lifecycle of the pipeline and contributes to maintaining data quality, efficiency, and usability.
1. Data Sources: Data sources are the origin points from which the pipeline collects information. These can include:
- Databases (SQL, NoSQL)
- APIs (payment gateways, social media, SaaS applications)
- IoT devices and sensors (temperature, telemetry, or industrial data)
- Files (CSV, JSON, XML, or logs)
The diversity and volume of data sources determine the complexity of the ingestion process and the type of pipeline architecture needed.
2. Ingestion Layer: The ingestion layer is responsible for collecting data from various sources and bringing it into the pipeline for further processing. It can handle both batch and real-time ingestion depending on the business requirements, ensuring flexibility for different use cases. This layer plays a crucial role in transferring data reliably and without loss, preparing it for the next stages of the pipeline. Popular tools used in this layer include Kafka, Fivetran, Debezium, and AWS Kinesis, which help automate and manage the ingestion process efficiently.
3. Processing Layer: Once data is ingested, it often needs to be cleaned, transformed, or enriched before it can be stored or used for analysis. The processing layer is responsible for applying these transformations to ensure the data is accurate, consistent, and analytics-ready. Key tasks in this layer include data cleaning, such as removing duplicates and fixing errors, standardizing and formatting data to maintain consistency, aggregating or summarizing information for easier analysis, and enriching datasets by joining them with additional sources. This layer ensures that downstream systems receive high-quality, reliable data for reporting, machine learning, and business intelligence. A robust processing layer ensures that downstream systems receive high-quality, analytics-ready data.
Popular tools: Apache Spark, Apache Flink, dbt.
4. Storage Layer: The storage layer provides a secure and scalable location to store processed data. This can be:
- Data Warehouses for structured analytics (Snowflake, BigQuery, Redshift)
- Data Lakes for raw and unstructured data (S3, Azure Data Lake)
- Lakehouses combining features of both (Delta Lake, Databricks)
Efficient storage ensures fast query performance, cost-effectiveness, and easy accessibility for business teams and applications.
5. Orchestration Layer: The orchestration layer manages the workflow of the entire data pipeline by scheduling tasks, handling dependencies, and automatically retrying failed jobs. It ensures that each step of the pipeline runs in the correct sequence and at the appropriate time, maintaining reliability and consistency across the system. Popular orchestration tools such as Airflow, Prefect, and Dagster are commonly used to automate and monitor these workflows, helping organizations streamline complex data processes and reduce manual intervention.
6. Monitoring & Observability: Monitoring and observability tools track the health, performance, and quality of the pipeline. They help detect anomalies, failures, or performance bottlenecks before they impact downstream processes. By implementing proper monitoring, organizations can maintain data accuracy, prevent downtime, and optimize pipeline performance over time.
Popular tools: Grafana, DataDog, Great Expectations.
6. ETL vs ELT
Data integration is a crucial part of any data pipeline, and two of the most common approaches are ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). While both processes aim to move and prepare data for analysis, they differ in the order of operations and their ideal use cases.
ETL (Extract, Transform, Load): In ETL, data is first extracted from source systems, then transformed (cleaned, formatted, and enriched) before being loaded into a data warehouse or storage system. ETL is best suited for structured data and traditional data warehouses where pre-processing before storage is preferred.
ELT (Extract, Load, Transform): In ELT, data is extracted from sources and loaded directly into the target system, such as a data warehouse or lakehouse, and then transformed within the storage platform. ELT leverages the computing power of modern cloud data warehouses and is ideal for large volumes of structured and unstructured data.
Key Differences:
| Feature | ETL | ELT |
| Order | Extract → Transform → Load | Extract → Load → Transform |
| Data Type | Structured | Structured & Unstructured |
| Processing Location | Outside the data warehouse | Inside the data warehouse/lakehouse |
| Ideal Use Case | Traditional on-premise warehouses | Cloud-based warehouses with scalable compute |
Use ETL when: ETL is best suited for scenarios where data needs to be cleaned and transformed before being stored. It works well with traditional or on-premise data warehouses and is ideal when data quality and governance are critical prior to loading. By transforming data before it reaches the warehouse, ETL ensures that only accurate and consistent data is stored.
Use ELT when: ELT is ideal for handling large volumes of raw data in modern cloud-based warehouses or lakehouses with high processing power. It allows you to store raw data first and then transform it as needed for different use cases, providing flexibility for analytics, reporting, and machine learning. ELT is particularly useful when multiple teams or applications need access to the same raw data for various purposes.
Popular Tools
- ETL Tools: Informatica, Talend, Pentaho – these are robust platforms designed for complex transformations and integrations across multiple systems.
- ELT Tools: dbt, Snowflake, BigQuery – modern tools that leverage cloud computing for in-warehouse transformations and real-time analytics.
ETL and ELT are both powerful approaches to building data pipelines. Choosing the right method depends on data volume, source type, processing requirements, and infrastructure. Understanding these differences ensures data is accurate, usable, and ready for analytics or machine learning.
7. Data Quality, Security & Governance
Data is one of the most valuable assets for any organization, but its value depends on how reliable, secure, and well-managed it is. Ensuring data quality, security, and governance is essential for building trust, compliance, and effective decision-making in any data pipeline.
Data Quality: Data quality ensures that the data used in a pipeline is accurate, complete, consistent, and up-to-date. Poor-quality data can lead to wrong insights and bad business decisions. Practices like data cleaning, validation, standardization, and continuous monitoring help maintain high-quality data that is reliable for analysis and reporting.
Data Security: Data security protects sensitive information from unauthorized access, breaches, and misuse. This includes implementing access controls, encryption for data at rest and in transit, and audit logs to track who accesses or changes the data. Strong security helps organizations comply with regulations and protect customer and business data.
Data Governance: Data governance sets the rules, policies, and responsibilities for managing data throughout its lifecycle. It includes defining data ownership, maintaining metadata, and ensuring compliance with regulatory and internal policies. Proper governance ensures that data is organized, consistent, and trustworthy, making it easier to manage and use effectively.
8. Future Trends & Innovations
The world of data pipelines is constantly evolving, driven by increasing data volumes, real-time demands, and advancements in cloud technologies. One major trend is the adoption of real-time and streaming pipelines, which allow businesses to act on data instantly for faster decision-making.
Automation and AI integration are also becoming more common, with intelligent tools helping to optimize workflows, detect anomalies, and improve data quality without human intervention. Additionally, serverless and cloud-native architectures are gaining popularity, offering scalable, cost-effective solutions that can handle large and complex datasets efficiently.
Another innovation is the rise of data mesh and decentralized data architectures, which allow organizations to manage data as a product, improving accessibility, ownership, and governance across teams. Finally, enhanced data observability and monitoring tools are helping companies gain better insights into pipeline performance, ensuring reliability and proactive problem resolution.
These trends indicate that future data pipelines will be faster, smarter, and more flexible, empowering organizations to leverage data more effectively for analytics, machine learning, and business growth.
9. FAQs: Data Pipelines
1. What exactly is a data pipeline?
A data pipeline is a system that collects data from multiple sources, processes it, stores it, and delivers it to applications, dashboards, or analytics tools. It ensures data flows efficiently from raw form to actionable insights.
2. What is the difference between ETL and ELT?
ETL (Extract, Transform, Load) processes data before loading it into a warehouse, making it ideal for structured data and traditional systems. ELT (Extract, Load, Transform) loads raw data first and transforms it later, which works well for cloud-based warehouses and large datasets.
3. Why are data pipelines important for businesses?
Data pipelines allow organizations to turn raw data into meaningful insights quickly and accurately. They help improve decision-making, support analytics and machine learning, automate reporting, and maintain data quality and consistency.
4. What are the main types of data pipelines?
The main types include batch pipelines (scheduled processing), real-time pipelines (instant updates), streaming pipelines (continuous high-volume data), hybrid pipelines (batch + real-time), and data lakehouse pipelines (combining raw and structured data).
5. How do modern data pipelines handle security and quality?
Modern pipelines implement data quality checks, validation, and standardization to ensure accurate data. Security measures like encryption, access controls, and audit logs protect sensitive information, while governance policies maintain compliance and accountability.
10. Conclusion
Data pipelines are the backbone of modern data-driven organizations. They ensure that raw data from multiple sources is collected, processed, stored, and delivered in a reliable and efficient way. By implementing the right type of pipeline, using appropriate architectures, and focusing on data quality, security, and governance, businesses can turn vast amounts of data into actionable insights.
With the rise of cloud technologies, real-time processing, AI-driven automation, and innovative architectures like data lakehouses and microservices, data pipelines are becoming faster, smarter, and more scalable. Whether for analytics, reporting, or machine learning, investing in well-designed data pipelines allows organizations to make informed decisions, stay competitive, and prepare for the future of data.
Moreover, data pipelines are not just technical tools—they are strategic assets that connect different teams, systems, and processes within an organization. By enabling consistent and timely access to accurate data, pipelines help drive innovation, improve operational efficiency, and empower businesses to respond proactively to market trends and customer needs. In short, mastering data pipelines is key to unlocking the full potential of data and building a truly data-driven enterprise.

November 26, 2025
Don’t Miss These Game-Changing Power BI Updates for...

November 26, 2025



